Hi @sampattuzzi.
I’m afraid your regex doesn’t quite match all non-isograms. You can check out here. This is because it appears to only say it’s not an isogram when the first letter in the word is repeated at the end. It’s a shame as yours looks a lot neater than mine.
As to why I did it the way I did. Ie, not using \w over [a-z] that is because using a regex it would not say a and A are the same. Also I did not want it to match numbers at all. So using just [a-z] and the tag std::regex_constants::icase worked for me.
And your question
No because of the negative lookahead included in the regex. John Woo did a nice explanation of a very similar regex here.
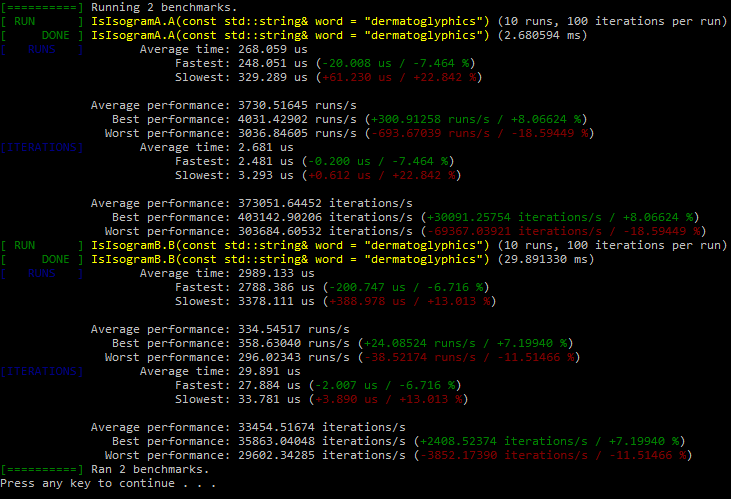
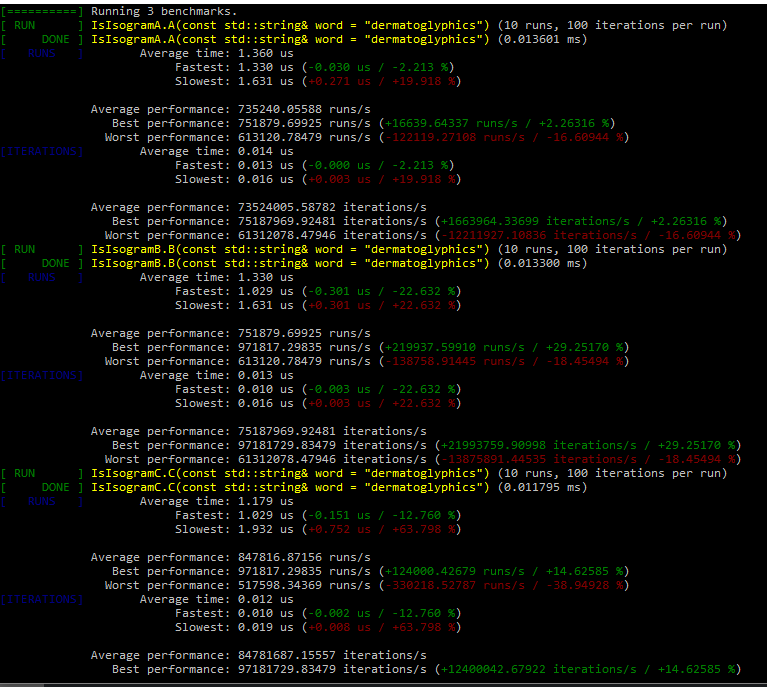
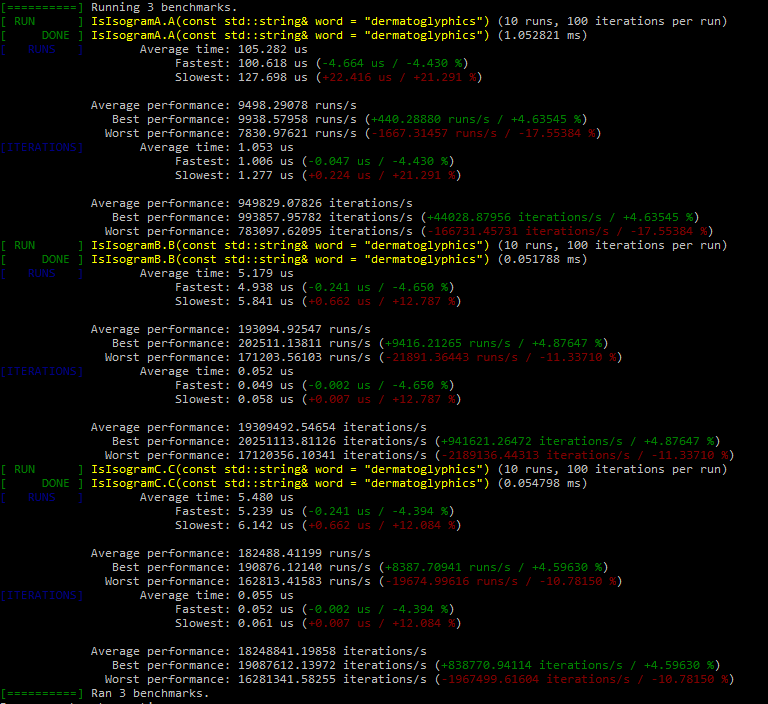
But I was actually interested in the performance side of using a regex vs using the way @ben showed in lecture 47. I would be interested if anyone had any comments on that as I do not know how to find out myself.