Hi @sampattuzzi.
I’m afraid your regex doesn’t quite match all non-isograms. You can check out here. This is because it appears to only say it’s not an isogram when the first letter in the word is repeated at the end. It’s a shame as yours looks a lot neater than mine.
As to why I did it the way I did. Ie, not using \w over [a-z] that is because using a regex it would not say a and A are the same. Also I did not want it to match numbers at all. So using just [a-z] and the tag std::regex_constants::icase worked for me.
And your question
No because of the negative lookahead included in the regex. John Woo did a nice explanation of a very similar regex here.
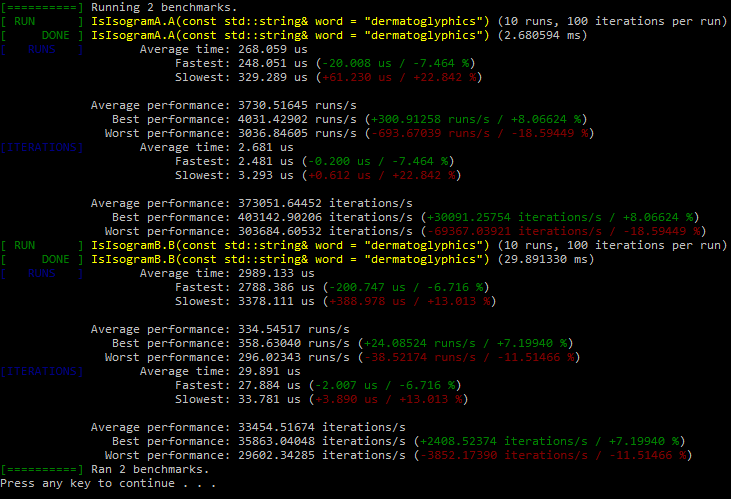
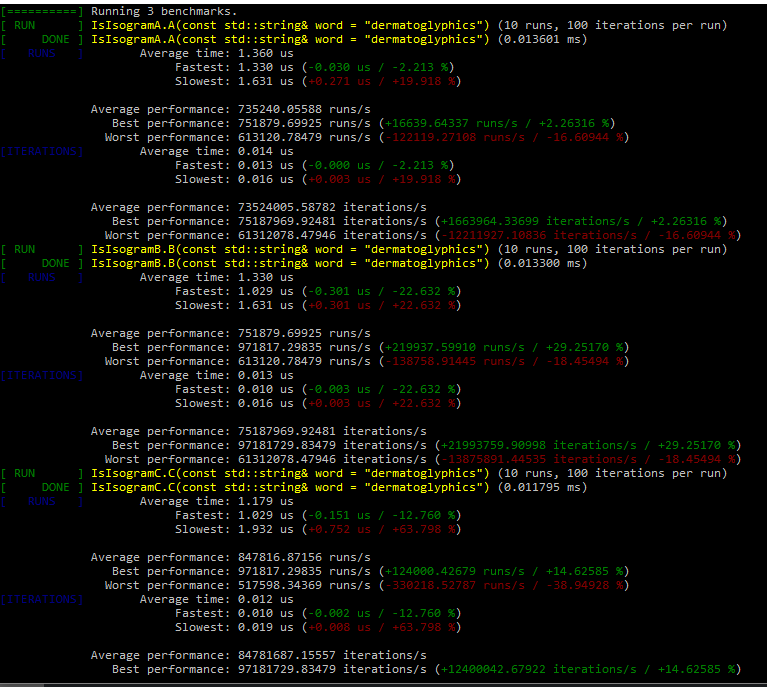
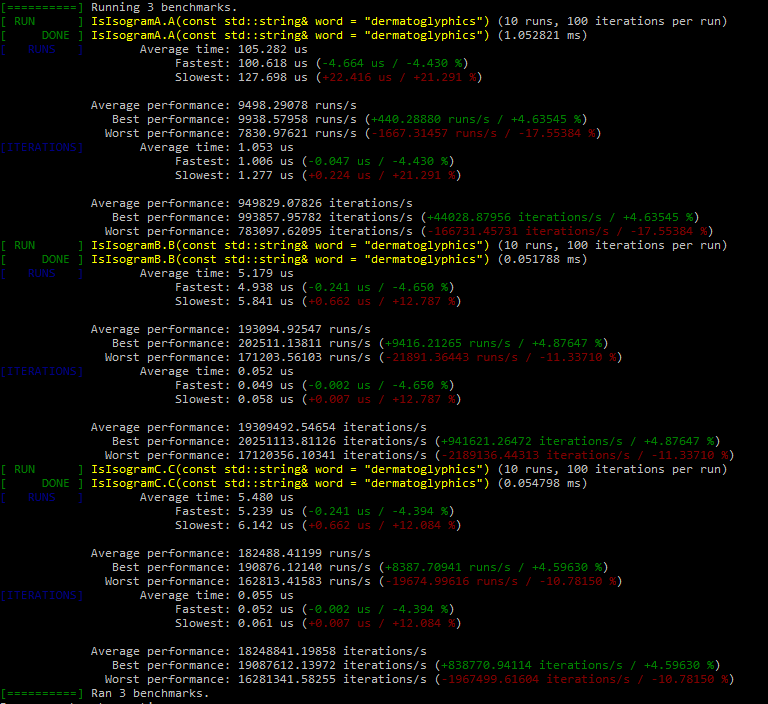
But I was actually interested in the performance side of using a regex vs using the way @ben showed in lecture 47. I would be interested if anyone had any comments on that as I do not know how to find out myself.
Yeah, messed up the [] () order originally and looks like I didn’t delete the ‘]’ when rearranging. Also there’s a far better solution than either of those methods.
If you don’t mind explaining, what solution would that be? I posted my alternative here, something along the lines of that or something completely different?
Pretty much that. Given that inputs are automatically converted to lowercase after input or rejected as invalid input then you could simply just do a count with a nested for loop and get the same results. I decided to test whether having your implementation as a count instead of a bool changed anything and it didn’t.
Nice, I didn’t think of the count idea; I would have thought it’d be slower because of the O(n^2) vs O(n) complexity but considering the longest isogram you could check would be 26 letters the scaling doesn’t matter all that much. I only had the tolower and isalpha in there to go along with the instructor’s idea that the tests shouldn’t rely on each other, but you’re right in this case it would be okay to get rid of those checks.
Yeah, I chose to just transform the input to lowercase in my build as it just makes things simpler and not needing to perform the same operations on the string (tolower) all the time.
Traversing a contiguous array like std::string is lightning fast and in the count all that’s happening is counting the current outter loop’s letter so the whole function is pretty fast. Changing the check to tolower(OtherLetter) == tolower(Letter) slows it down considerably making the average time go up to ~100 us.
Though like you said this function (in English) would have to end at a maximum of 26 letters, though even using every currently used language I doubt the count algorithm would be worse than inserting into a map.