Not a silly question.
- It is most likely done that way because the data is reset every time a new guess is made, so the data isn’t really persistent (every time we reset the values back to 0). All the other data in private is a little more persistent, needed over the lifetime of a round or during the whole game.
Personally I ended up simplifying a few of the functions that seemed to be broken up a little needlessly, but keeping a function small does make it simpler to understand.
- Hopefully I understand correctly, if not just clarify.
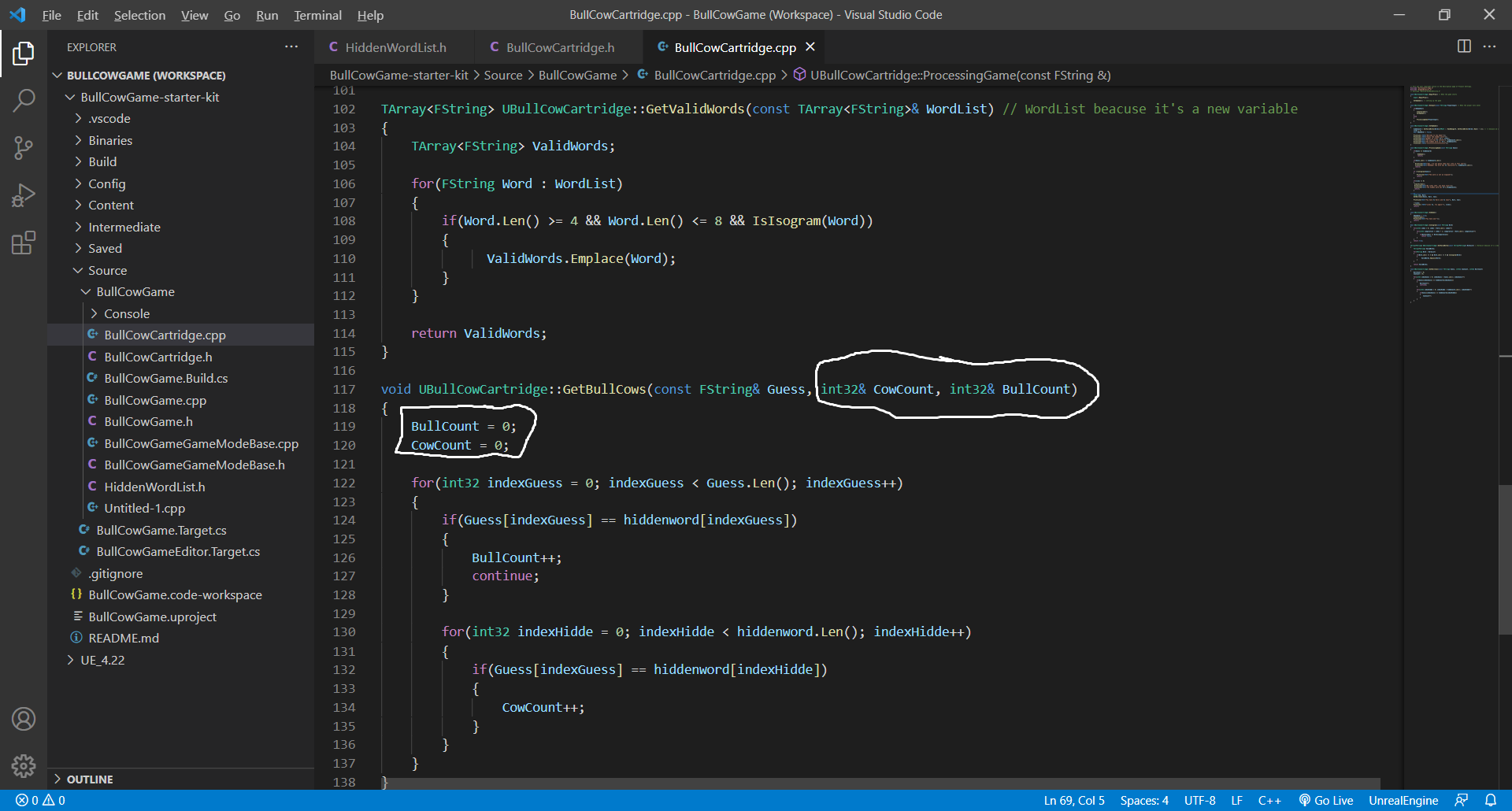
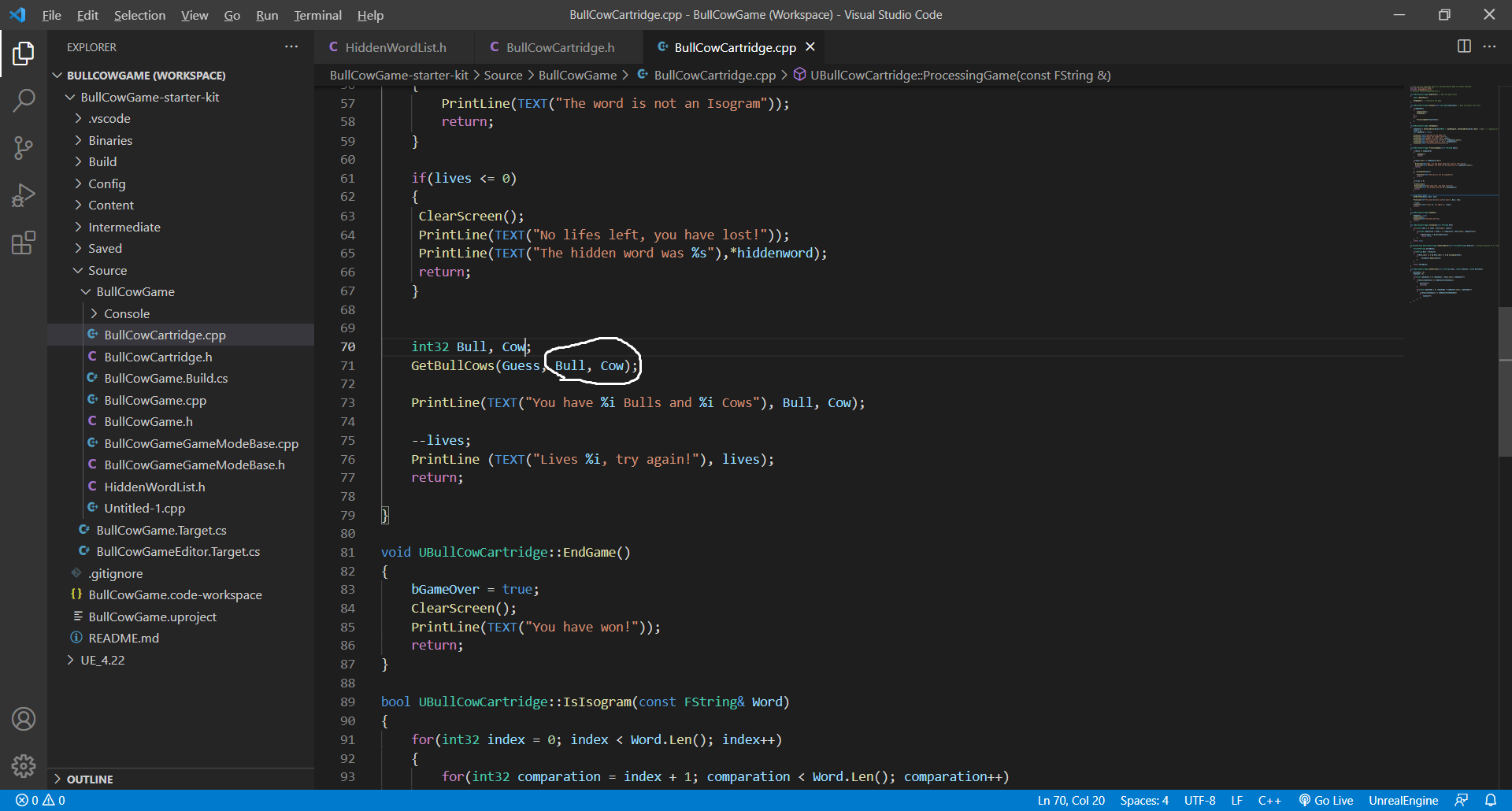
int32 Bull, Cow; // This creates storage for the variables
GetBullCows(Guess, Bull, Cow); // This passes the address of the storage
The variable names are only known in the scope they are declared, and are not known in the GetBullCows function scope. The GetBullCows function only cares that it is the same type (int32, FString, etc). The only variables that are seen everywhere in the class are those in the class header file (hiddenword, lives, bGameOver) or from it’s parent (it inherits from UCartridge).
// The names of the parameters in this method are only local and only apply
// to the function itself. You can call this method with any variable names you
// want. But it helps to make them understandable from the calling code.
void UBullCowCartridge::GetBullCows(const FString& Guess, int32& CowCount, int32& BullCount)
{
}
// I can call this with the following, of course it is much less readable
int32 Goat, Sheep;
FString Word;
GetBullCows(Word, Sheep, Goat);
So if you’re just asking why not name the integers “BullCount” and “CowCount”… well you could. And it might make the code more readable in this case. But maybe the reason is to get the student used to not always having things named the same (often the case). Or maybe it was just to keep it short and simple (programmers often do this if words start getting long).
Hopefully that explains it. Let me know if something isn’t clear with that.