I’d like to share how I tend to use git (generally with GitHub or Bitbucket) using the graph and history of one of my ‘day job’ (non-Unity but still c#) projects, rather than my ‘first git branch screenshot’, just as I hope it may end up having value to someone to see what the future holds after using it consistently and extensively for a longer timeframe.
Apart from being a c# dev I get to oversee a number of other devs for around 100 repos. Not everyone in our company uses the same workflows for various reasons, but when I coach more junior users I tend to have a preference or bias one way, but we allow them to go off and develop adjustments to it as needed.
This project I’ve been working on for a little over a year now, for context it’s a c# client app with around 65k lines of code, over 400 commits, about 15 releases (approx. monthly cadence). So not massive (I’ve worked on code bases more than 20-30x this size before) but fair effort for the timeframe and resources given I’m really the only contributor to this piece of it.
Here’s what it looks like in Visual Studio’s branch-history view, which is a graph view I use more than most others actually.
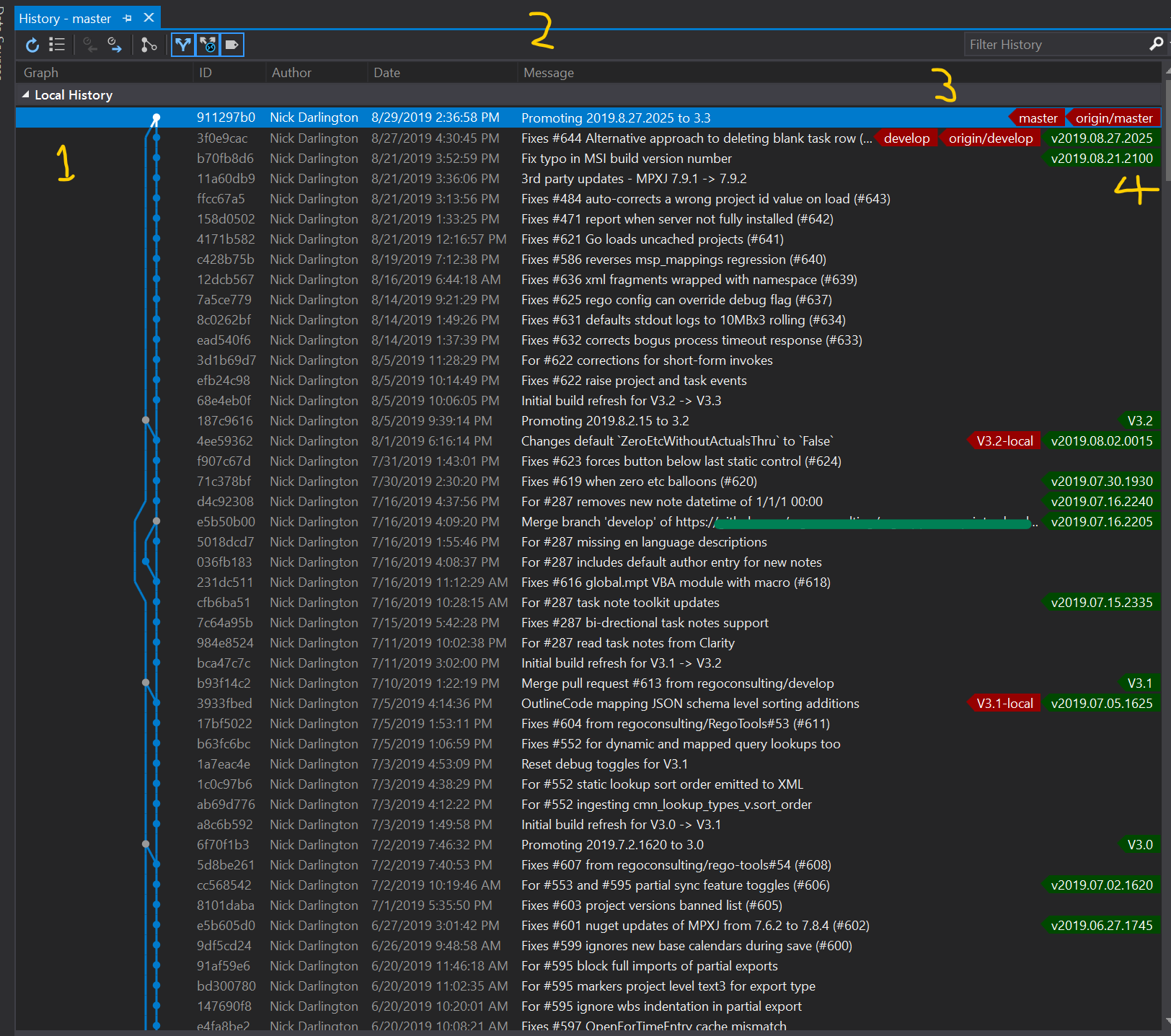
A few areas I wanted to draw attention to in it were:
- Branching flow
- You can see it’s a reasonably “clean” looking flow, not much spaghetti action going on here. It’s a personal tweak on “git flow” (a named methodology for how to branch and update your code). I like clean!
1b. Lifetime branches
- On the left you’ll see Master, the first branch created, but once created only ever Merge-Committed into (using a pull request) from Develop when it’s time to release.
- On the right is Develop, my “currently working on to try and release” code line that needs to also be “always working”, no commit that knowingly breaks the code should be submitted to it. This branch gets created the instant I have done the initial commit, and then in GitHub is set to my default branch for pull requests etc.
- I VERY RARELY commit ANYTHING directly to Develop either. Instead, as we’ll come to, you’ll find that any time a piece of work comes up that needs to be done, an issue is created for it in GitHub (or Jira w/Bitbucket). That way even if I don’t work on it for a few months, by the time I get back to it, I still know what it is, what to do, and why it’s being done. If I don’t get to it, I have no code loose ends left behind.
1c. Transient branches
- Instead, once I have an issue, and I’m decided that it’s the next feature/fix I am going to tackle, I create ANOTHER branch off of Develop (a “feature branch”).
- As I work on the feature branch, I will do regular commits as needed until it’s working to my satisfaction and I’m ready to hand it over for QA testing. It’s at that point I will merge it back into Develop, but I do so in a way that lets me DELETE the feature branch whilst not losing my code or the issue it’s related to.
- Of the 3 pull request merge operations in (say) GitHub, when it’s between a feature branch and develop, I will ONLY use Squash or Rebase options.
- Rebase and merge into Develop has the effect of detaching my feature branch from wherever it was on the Develop line, and re-applying it a copy of all its commits onto the very end of Develop. If the commits were multiple and reasonably complex enough in more than one of them, I may want to keep them this way for future reference and hence the choice to Rebase works for me.
- Squash behaves similarly except (as its name implies), it takes all my commits of the feature branch and squashes them into 1 new one, which is applied to the end (head) of Develop. Handy if for example I did 1 complex commit in the feature branch but then realized I missed a minor change or had a minor error, and had to do more commits to correct those. When it comes time to be done with this feature, I may prefer to just have them all represented by 1 commit as the minor ones add little/no value.
1d. Cleanup
- After the squash or rebase, tools like GitHub will conveniently tell you that the feature branch is now safe to be deleted - this is because all of the same work within it now also lives under the domain of another branch (Develop).
- When I see that message, in VS or wherever, I switch from my feature branch to Develop and pull the updated squash/rebase/merge commits back down for it (as they were created directly in GitHub or whichever remote you were using, and I don’t yet have that new information local).
- At this point I can verify my changes are showing in the history on Develop as I intended and agree that GitHub has made the right assessment.
- Now I delete my local “feature branch”
- When that is done, I go ahead and also delete the remote version of the “feature branch”. Note that I delete them in that order due to limiting the number of cautions that VS will throw my way unnecessarily about potentially (but not really) losing any work by doing these actions.
- Now I’m ready to move onto the next issue and create another new feature branch for the next piece of work. And so it goes on.
- Smart commit labels
- You’ll see a number of my issues begin with things like “Fixes #123” or “For #456” and this is intentional. Although the syntax and referencing between GitHub issues (used here) and Jira issues (like ABC-1234) differ, both systems support the concept of smart commit labelling, which basically means using them can make some automatic and consistent updates in your repository for you.
- If I am adding just a contributory commit to an issue that doesn’t (finally) resolve it, I use “For #456”, which will then show up in my issue’s communication history at the time it took place.
- If I’ve done solving the issue I’ll use “Fixes #456” which has the added bonus of automatically closing the issue and linking to it in the communication history, when the commit is part of a pull request that gets merged from my feature branch over into Develop.
- Git / GitHub / etc. are tools for developers by developers, and unlike any other IT/tech departments I know of, really have a focus on efficiency and avoiding duplication of work and data entry, so automatically managing your issue state and having links to see the commit messages directly etc., are valuable and worth taking the time to get used to using. It becomes second nature real fast.
- In addition, no matter what branches are left over in my project, even if it’s just “clean” lifetime ones, it’s real easy for me to see which commits and code file changes were part of solving that issue, as they’re all listed together in the pull requests and associated issue communications trail.
- As an aside, I also use github’s milestones and project features, so having issues automatically change their status and even change how they appear in those items, gives me a quick overview of where I am with a release and what’s done vs. what’s outstanding, without having to deal with all the global clutter (of things which may be a few releases away) at once.
- Branches
- I’ve already covered my branching flow and what’s lifetime vs. transient, so not much else to say here. Only that in addition to generally having the Develop lifetime branch local (and Master local to whichever machine is building/signing/shipping the releases), all others have been cleaned up with the exception of a couple of others for the most recent builds I released for ease of access when I need to switch back to help support some problem or test some behavior specific to it.
- Hence the V3.1-local and V3.2-local ones, in time and now that we’ve just launched V3.3 I’ll probably create a new one for that as I begin work on the V3.4 stuff in Develop and features, and discard the V3.1-local one (provided enough of my users have upgraded from it that I won’t need it much anymore).
- Don’t worry too much about deleting branches that are merged completely into some other branch, as those local ones are into Develop. I will not lose any commits by doing so, as nothing uniquely belongs to them, and I can always go back and recreate them if needed temporarily; it’s not something I have to do at the time or else I’m stuck.
- Tags
- How you use these is up to you, tags are basically “labels” like branch labels are, except they just attach to a commit and do not “move”, whereas commiting to a branch (directly or with a merge) causes the branch label to “move up” to the top of the line of that commit chain. Tags won’t do so.
- Here I have 2 tag strategies only, I like using lower-case vYYYY.MM.DD.HHMI format for internal releases, meaning certain points in the life of features being committed to Develop but before Develop is ready to ship out to the world.
- You can name yours however you like, but using this reference makes it easier for me to put things in context when a tester or other person comes up and says such-and-such isn’t working and I’m sure I’ve fixed it, and when I ask which tag/version they are using, I find it’s one from a couple months ago and they need to upgrade.
- Sometimes in projects I control I’ll use that same system for shipped releases too (maybe with an upper-case V instead, and maybe not), but in this particular case it was the preference of other non-coders on the team that I use a simple VMajor.Minor scheme instead, hence every build that is ultimately shipped and released gets shrunk down to just something like V3.2.
- You can use tags for other things, maybe just like “todo” indicators where you know something is a bit wonky and needs looking at, or as references to past pain-points in case you need to quickly reference the logic changes that were needed then, and so on. I’m not really advocating or pushing for a specific use here, just explaining why you see what you see.
- They are versatile, just note that they’ll show up as tags in GitHub if pushed there too, and can be turned into “releases” there, so you may not want too much tags clutter to be pushed there. For instance, even though my repository has around 15-20 real releases (I don’t actually know the exact number off hand), GitHub shows >100 releases available because of all the other tags too.
This is likely NOT the best way to use Git/GitHub, since I truly believe the best way is subjective. I will adapt to a common team standard of branching and labelling and committing/reviewing as makes best sense on a case by case basis; it’s really not that hard to do once you get used to doing it.